golang map
概述
和 map 相关的操作主要是:
- 增加一个 k-v 对 —— Add or insert;
- 删除一个 k-v 对 —— Remove or delete;
- 修改某个 k 对应的 v —— Reassign;
- 查询某个 k 对应的 v —— Lookup;
简单说就是最基本的 增删查改。
Go 语言采用的是哈希查找表,并且使用链表解决哈希冲突。
表示 map 的结构体是 hmap
bmap 就是我们常说的“桶”,桶里面会最多装 8 个 key,这些 key 之所以会落入同一个桶,是因为它们经过哈希计算后,哈希结果是“一类”的。在桶内,又会根据 key 计算出来的 hash 值的高 8 位来决定 key 到底落入桶内的哪个位置(一个桶内最多有8个位置)
每个 bucket 设计成最多只能放 8 个 key-value 对,如果有第 9 个 key-value 落入当前的 bucket,那就需要再构建一个 bucket ,通过 overflow 指针连接起来。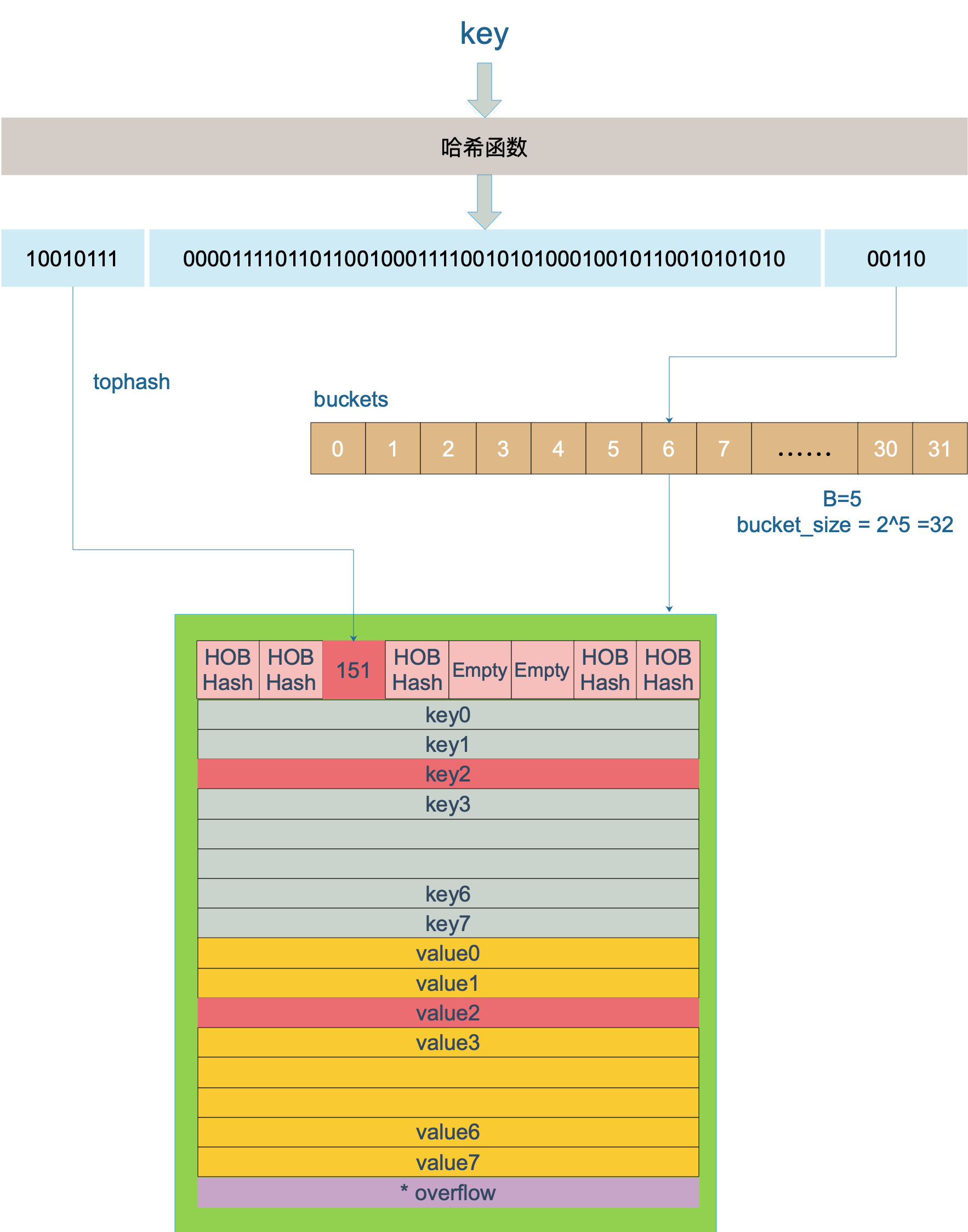
上图中,假定 B = 5,所以 bucket 总数就是 2^5 = 32。首先计算出待查找 key 的哈希,使用低 5 位 00110,找到对应的 6 号 bucket,使用高 8 位 10010111,对应十进制 151,在 6 号 bucket 中寻找 tophash 值(HOB hash)为 151 的 key,找到了 2 号槽位,这样整个查找过程就结束了。
如果在 bucket 中没找到,并且 overflow 不为空,还要继续去 overflow bucket 中寻找,直到找到或是所有的 key 槽位都找遍了,包括所有的 overflow bucket。
扩容
使用哈希表的目的就是要快速查找到目标 key,然而,随着向 map 中添加的 key 越来越多,key 发生碰撞的概率也越来越大。随着向 map 中添加的 key 越来越多,bucket 中的 8 个 cell 会被逐渐塞满,接近退化成链表,各种操作的效率直接降为 O(n)
需要有一个指标来衡量前面描述的情况,这就是装载因子。Go 源码里这样定义 装载因子:
1 | |
count 就是 map 的元素个数,2^B 表示 bucket 数量。
再来说触发 map 扩容的时机:在向 map 插入新 key 的时候,会进行条件检测,符合下面这 2 个条件,就会触发扩容:
- 装载因子超过阈值,源码里定义的阈值是 6.5。
- overflow 的 bucket 数量过多:当 B 小于 15,也就是 bucket 总数 2^B 小于 2^15 时,如果 overflow 的 bucket 数量超过 2^B;当 B >= 15,也就是 bucket 总数 2^B 大于等于 2^15,如果 overflow 的 bucket 数量超过 2^15。即:
B<15 cnt(overflow bucket) > cnt(bucket)
B>=15 cnt(overflow bucket) > 2^15
for case 1: 平均每个 bucket 中存放了超过6.5个 kv
for case 2: 本质上是 key 的 hash 特征趋同
1 多次循环 插入大量但未达到 case 1 的元素,然后删除其中部分元素,致使出现了 大量 overflow bucket, 即 kv 不多,但 overflow bucket 很多
2 就是 key 的 hash 特征恰好一致,未达到分流的效果(此时golang的扩容策略无效 因为问题不是容量的问题 是hash算法的问题 应该无解 或者做丑陋的patch)
由于 map 扩容需要将原有的 key/value 重新搬迁到新的内存地址,如果有大量的 key/value 需要搬迁,会非常影响性能。因此 Go map 的扩容采取了一种称为“渐进式”地方式,原有的 key 并不会一次性搬迁完毕,每次最多只会搬迁 2 个 bucket。
对于条件 1,元素太多,而 bucket 数量太少,将 B 加 1 :
bucket 最大数量(2^B)直接变成原来 bucket 数量的 2 倍。就没这么简单了。要重新计算 key 的哈希,才能决定它到底落在哪个 bucket。例如,原来 B = 5,计算出 key 的哈希后,只用看它的低 5 位,就能决定它落在哪个 bucket。扩容后,B 变成了 6,因此需要多看一位,它的低 6 位决定 key 落在哪个 bucket。这称为 rehash。
对于条件 2,元素没那么多,但是 overflow bucket 数特别多,说明很多 bucket 都没装满。解决办法就是开辟一个新 bucket 空间,将老 bucket 中的元素移动到新 bucket,使得同一个 bucket 中的 key 排列地更紧密。这样,原来,在 overflow bucket 中的 key 可以移动到 bucket 中来。结果是节省空间,提高 bucket 利用率,map 的查找和插入效率自然就会提升。
从老的 buckets 搬迁到新的 buckets,由于 bucktes 数量不变,因此可以按序号来搬,比如原来在 0 号 bucktes,到新的地方后,仍然放在 0 号 buckets。
在搬迁过程中,oldbuckets 指针还会指向原来老的 []bmap,并且已经搬迁完毕的 key 的 tophash 值会是一个状态值,表示 key 的搬迁去向。
在插入、修改、删除 key 以及遍历的时候,都会尝试进行搬迁 buckets 的工作。先检查 oldbuckets 是否搬迁完毕,具体来说就是检查 oldbuckets 是否为 nil。
遍历
遍历所有的 bucket 以及它后面挂的 overflow bucket,然后挨个遍历 bucket 中的所有 cell。每个 bucket 中包含 8 个 cell,从有 key 的 cell 中取出 key 和 value。
开始在哪个 bucket 以及在 bucket 中哪个 cell 开始遍历是通过生成随机数 然后进行位运算决定的
插入
对 key 计算 hash 值,根据 hash 值按照之前的流程,找到要赋值的位置(可能是插入新 key,也可能是更新老 key)
删除
删除操作同样是两层循环,核心还是找到 key 的具体位置。寻找过程都是类似的,在 bucket 中挨个 cell 寻找,找到对应位置后,对 key 或者 value 进行“清零”,最后,将 count 值减 1,将对应位置的 tophash 值置成 Empty
float 类型作为key
float 类型可以作为 map 的 key ,当用 float64 作为 key 的时候,先要将其转成 uint64 类型,再插入 key 中。但是由于精度的问题,会导致一些诡异的问题,慎用之。
线程安全
- 边遍历边删除,遍历的结果就可能不会是相同的了,有可能结果遍历结果集中包含了删除的 key,也有可能不包含,这取决于删除 key 的时间:是在遍历到 key 所在的 bucket 时刻前或者后
- 多协程并发写 会触发 concurrent map writes
- 多协程并发读写 会触发 concurrent map read and map write
- 多协程并发遍历/写 会触发 concurrent map iteration and map write